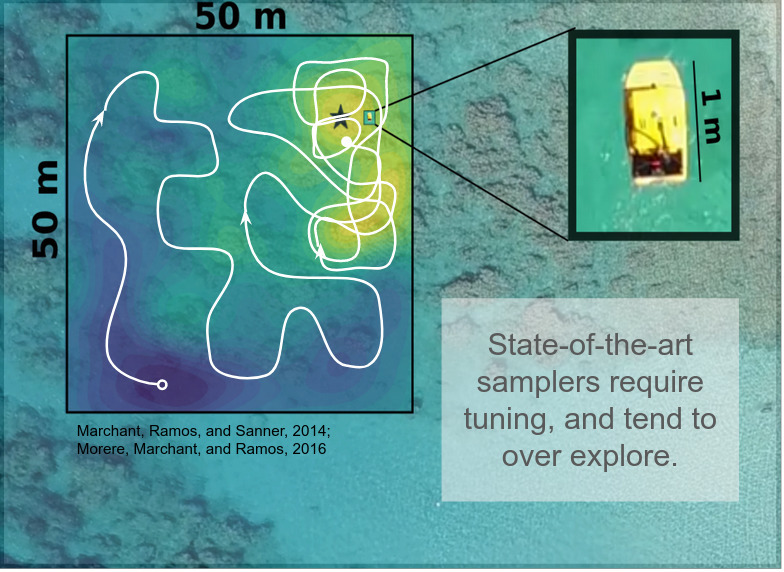
PLUMES: Maximum Seek-and-Sample
In many environmental and earth science applications, experts want to collect scientifically valuable samples of a maximum. Maximums may be analogous to sources in an environment---for instance, the site of a wastewater outfall in a river---or may more abstractly represent any location in a world that is "most interesting" for some given scientific query. The maximum seek-and-sample (MSS) problem formalizes the idea that we would like to find the maximum in a world, and then densely collect samples from that maximum. Since we assume that a target environment is initially unknown, we need to perform search. Canonical strategies, like lawnmowing, can lead to collecting very few samples of the maximum. Greedy strategies, in which the robot chases positive gradients, in realistic environments can arbitrarily converge to a local maxima. State of the art strategies, which overcome poor convergence in greedy systems by optimizing over sequences of actions, tend to over-explore an environment due to an overly general treatment of a reward measure.


To formulate a more effective planner for this problem, there are three core challenges to overcome: (1) plannng under uncertainty with partial observability, (2) searching over continuous state and observation spaces, and (3) overcoming a sparse reward signal. In our approach, PLUMES: Plume Localization under Uncertainty using Maximum-valuE information and Search, each of these challenges is mapped to a different piece of a robotic decision-making system respectively: the model, the planner, and the search heuristic.
A Model for Planning Under Uncertainty
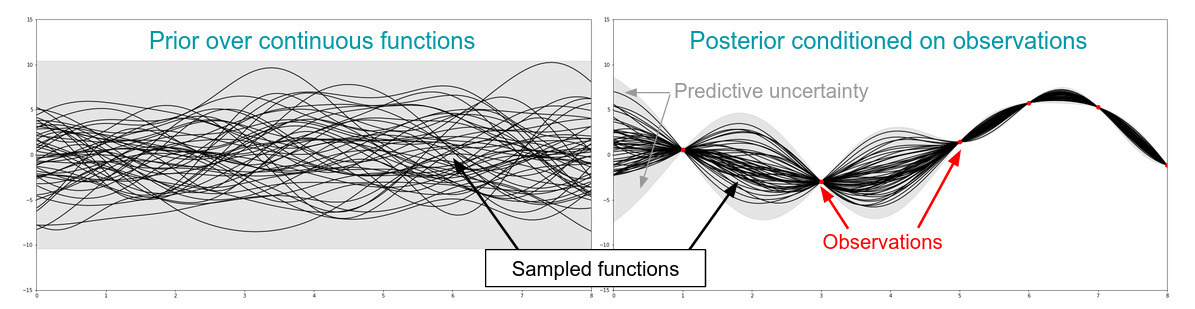
Partial observability is the notion that each observation of some target distribution, reveals only a very little of the distribution. For example, in environmental sampling, we might be interested in measuring the distribution of a chemical field in the atmosphere, but only have equipment that "sips" the air in small parcels to measure concentration. To actually get the form of the underlying distribution from these measurements, we will use a probabilistic model which allows the robots belief about an environment to be built from its observations. A particularly popular model for this in robotic sampling problems is a Gaussian Process (GP), which places a probability distribution over the continuous space of functions that could represent the underlying environment. GPs are parameterized by a mean function and kernel function, the latter of which allows for us to inject prior knowledge about the relatedness of the data. For instance, if we expect the points in an environment near each other are correlated, we can encode that as a radial basis function in the GP.
Planning in Continuous Domains
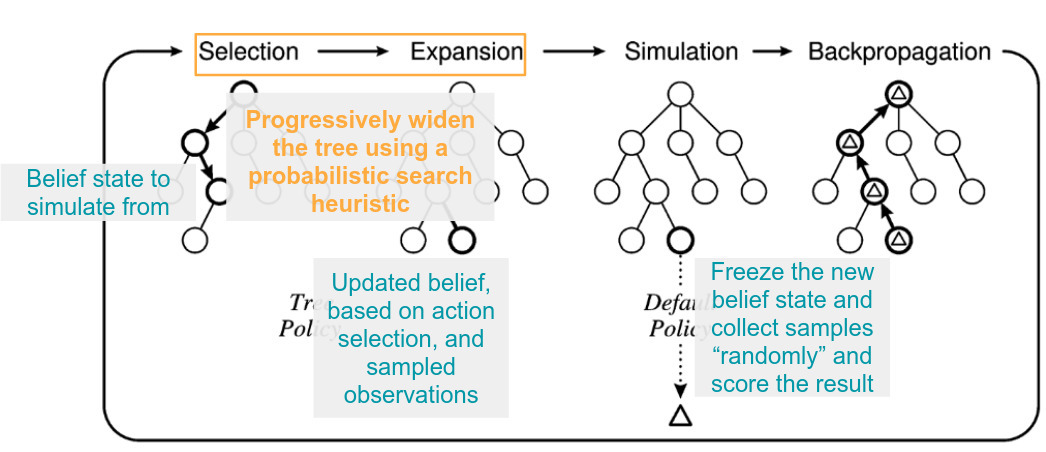
With a model in hand, we can consider how we'll exploit the model to select good actions to take. Since environments are continuous, exhaustive search over all possible actions that can be taken in all possible worlds is intractable. Instead, we would like a more targeted approach so that only the most promising actions are simulated. Continuous-observation Monte Carlo Tree Search is our proposed approach. Vanilla MCTS typically consists of four stages: selection, expansion, simulation, and backpropagation. During the selection phase, a possible world configuration is drawn from the GP belief state. In expansion, the selected world is updated according to some proposed action sequence. In the simulation phase, the robot's belief is frozen and a random series of actions is simulated in the environment. At the end of the simulation, the reward of the total trajectory is computed and backpropagated up the tree. The next node to expand is selected based on histories of simulations. In continuous environments, the tree in MCTS is likely to grow very wide, and not give a good estimate of expected reward for any node. Continuous-observaton MCTS instead will probabilistically revisit a previously drawn state in order to progressively widen the search tree.
Overcoming Sparse Reward
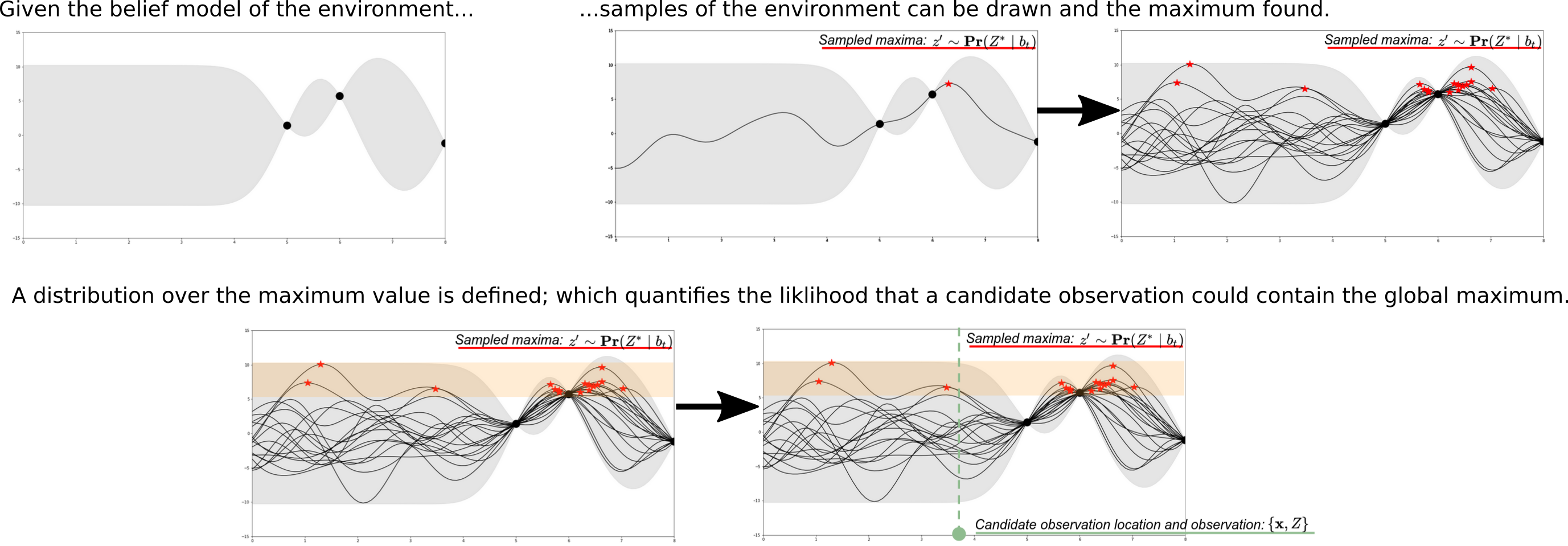
The last ingredient that we need is a reward heuristic to optimize. Recall that we would ultimately like to densely sample from the maximum in the environment. Reward placed only at the maximum is representative of a sparse reward function. Optimizing over sparse reward signals is an open problem; we would much rather optimize over a reward that encourages the robot to initially explore the world to get a good estimate of where the maximum is and then exploit that knowledge for sample collection. To define a heuristic reward we will use the intuition that exploiting the maximum of an environment requires reducing the uncertainty about the location of the maximum as quickly as possible. This translates into maximum value information, a reward measure defined as the mutual information between a candidate observation and the unknown global maximum value conditioned on a given belief about the world. The process for computing this type of information measure is described here, and is illustrated below. By leveraging the GP belief, samples of the estimate of the global maximum can be drawn and define a new distribution over the maximum value. For a given candidate observation, the likelihood that the maximum value could be observed there can be used to quantify the reward of that location. As more and more observations are taken as the mission progresses, the estimate of the maximum value becomes better, and eventually converges to placing reward only at the true maximum, encouraging exploitative sampling behaviors.
Outcomes and Conclusions
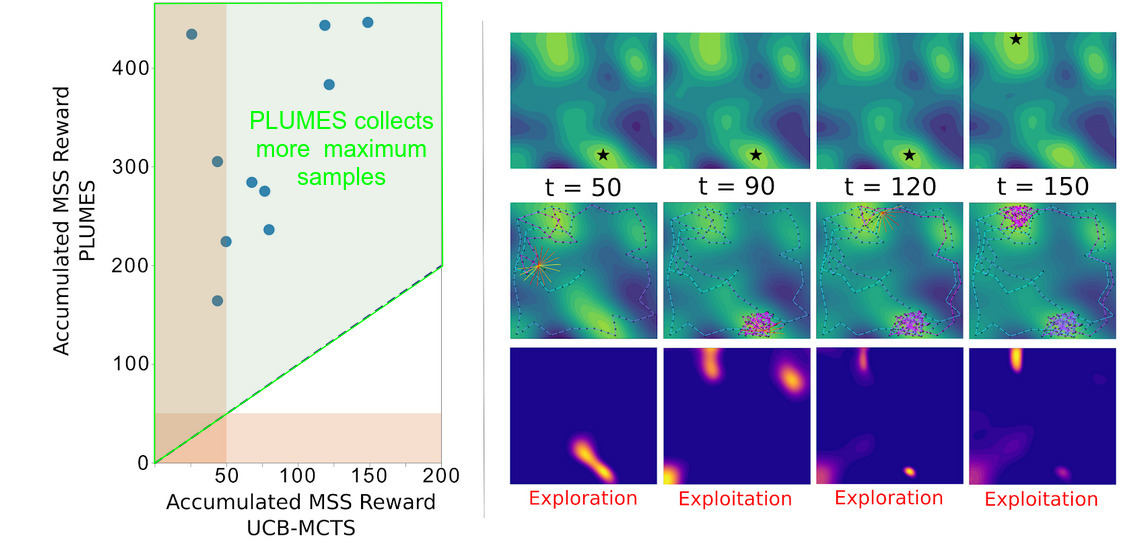
Taken together, PLUMES represents a novel extension to state of the art robotic samplers in order to address the unique challenges of maximum sampling. In static environments without any obstacles, a robot with PLUMES onboard is able to collect significantly more samples of the maximum than state of the art baselines, a lead that is extended when obstacles are present in the environment. Notably, PLUMES is able to learn the underlying distribution of the environment with the same accuracy to other models, indicating that PLUMES is more data efficient than other methods, by virtue of continuous-observation MCTS and maximum-value information reward.
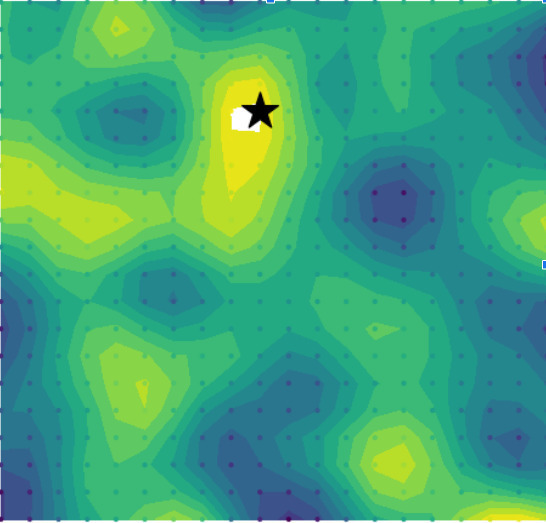

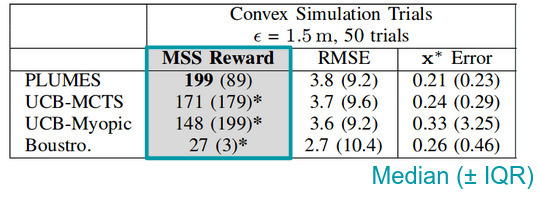
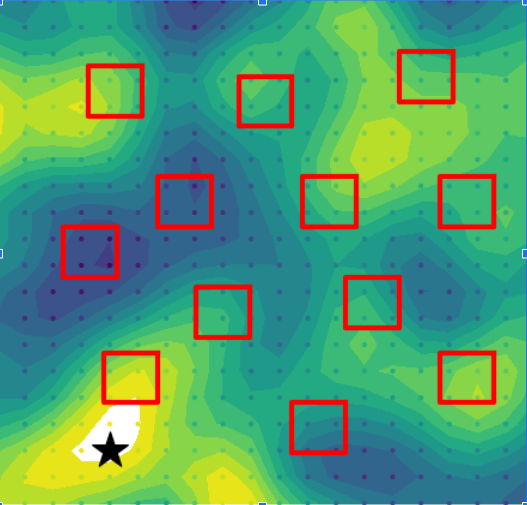
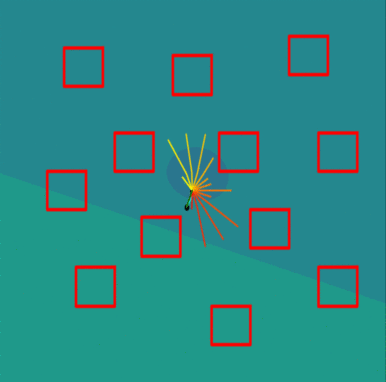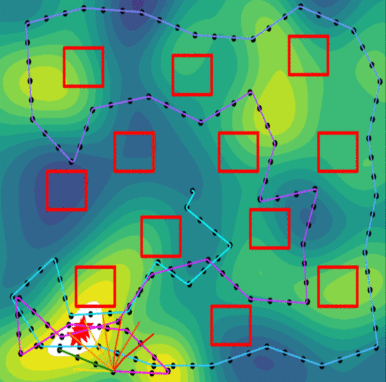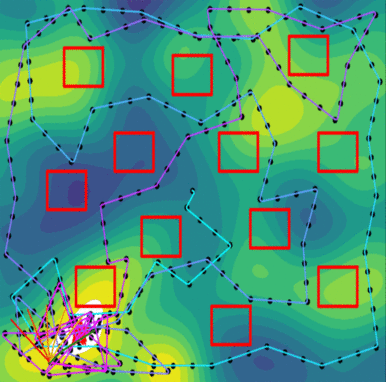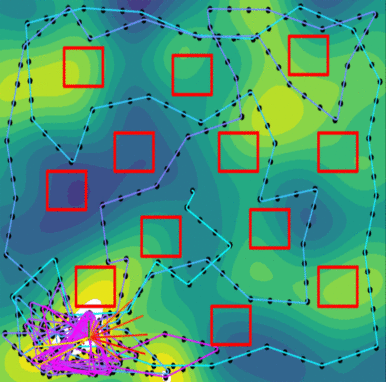

Further studies showed that the PLUMES framework was suitable for tracking time-varying maximum in simple environments, demonstrating cyclic explore-exploit behaviors by virtue of the maximum-value information reward. In these trials, PLUMES significantly outperformed the next best baselines.
![]()
PLUMES is a novel approach for global maximum seek-and-sample that shows that maximum-value information is a powerful new heuristic measure for sample-efficient model leanring and exploitation that is enabled by virtue of choosing a GP model for robot belief; and continuous-observation MCTS improves upon vanilla MCTS to assist in identifying more effective actions.